

图灵奖大佬 Lecun 发表对比学习新作,比 SimCLR 更好用! 11
文 | Rukawa_Y 编 | 智商掉了一地,Sheryc_王苏 比 SimCLR 更好用的 Self-Supervised Learning,一起来看看吧! Self-Supervised Learning作为深度学习中的独孤九剑,当融汇贯通灵活应用之后,也能打败声名在外的武当太极剑。比如在NLP领域中,每当遇到文本分类的问题,BERT + funetuning的套路来应对,但是也正因为如此大...
文 | Rukawa_Y 编 | 智商掉了一地,Sheryc_王苏 比 SimCLR 更好用的 Self-Supervised Learning,一起来看看吧! Self-Supervised Learning作为深度学习中的独孤九剑,当融汇贯通灵活应用之后,也能打败声名在外的武当太极剑。比如在NLP领域中,每当遇到文本分类的问题,BERT + funetuning的套路来应对,但是也正因为如此大...

卖萌屋的作者们,最近可真是忙秃了头~,不仅要苦哈哈地赶 ACL 2022 提前了两个月的Deadline,还要尽心尽力为读者们提供高质量的内容。如果大家心疼卖萌屋的作者们的话,还请多多一键三连:) ACL2022 全部转向了使用 ACL Rolling Review(ARR) 投稿,所有的投稿必须提交到 ARR 11 月及其之前的 Rolling Review (每月可以投稿一次)。考虑到大多数 ...

众所周知,命名实体识别(Named Entity Recognition,NER)是一项基础而又重要的NLP词法分析任务,也往往作为信息抽取、问答系统、机器翻译等方向的或显式或隐式的基础任务。在很多人眼里,NER似乎只是一个书本概念,跟句法分析一样存在感不强。一方面是因为深度学习在NLP领域遍地开花,使得智能问答等曾经复杂的NLP任务,变得可以端到端学习,于是分词、词性分析、NER、句法分析等曾经...

前言 今天要与大家分享的是AllenAI今年发表的最新工作,Longformer——一种可高效处理长文本的升级版Transformer。作者团队提供了开源代码,大家可快速复现,直接用于自己的任务。 传统Tranformer-based模型在处理长文本时有着天然的劣势。因为传统模型采用的是“全连接”型的attention机制,即每一个token都要与其他所有token进行交互。其attention复...
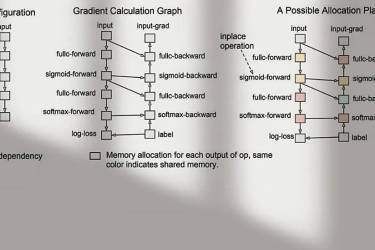
一只小狐狸带你解锁 炼丹术&NLP 秘籍 前言 虽然TPU的显存令人羡慕,但是由于众所周知的原因,绝大部分人还是很难日常化使用的。英伟达又一直在挤牙膏,至今单卡的最大显存也仅仅到32G(参考V100、DGX-2)。然而,训练一个24层的BERT Large模型的时候,如果sequence length开满512,那么batch size仅仅开到8(有时候能到10)就把这寥寥32G的显存打满...
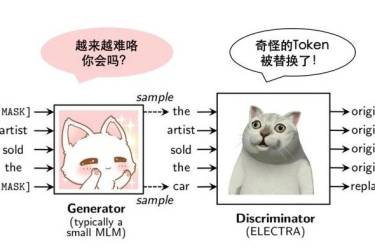
一只小狐狸带你解锁 炼丹术&NLP 秘籍 还记得去年写下《ELECTRA: 超越BERT, 19年最佳NLP预训练模型》时兴奋的心情,在我等到都快复工的时候,终于看到了它的身影和源码[1]: 才第五吗?没事,期望越大,失望越大 谷歌在github放出的预训练模型效果是这样的: 燃!鹅!在论文中声称的效果却是这样的 Github repo中官方的解释是精调的震荡比较大,他们测试了很多随机种子...

今天给大家带来的是一篇号称可以自动建立知识图谱的文章《Language Models are Open Knowledge Graphs》,文中提出了一个叫Match and Map(MAMA)的模型,无需人工!无需训练!只需语料和预训练好模型,就可以从头建立出知识图谱,甚至可以挖掘出人类发现不了的新关系。当Wikipedia再次邂逅BERT,知识图谱就诞生啦! 通常来说知识图谱的建立需要人工定义...

整理 | Jane出品 | AI科技大本营【导语】近日,百度提出知识增强的语义表示模型 ERNIE(Enhanced Representation from kNowledge IntEgration),通过对词、实体等语义单元的掩码,使得模型学习完整概念的语义表示。在语言推断、语义相似度、命名实体识别、情感分析、问答匹配等多项中文 NLP 任务上表现出色,有些甚至优于 BERT 在处理同类中文任...
随着大模型的发展,NLP领域的榜单可说是内卷到了无以复加,现在去浏览各大公开榜单,以至于各个比赛,随处可见BERT、RoBERTa的身影,甚至榜单中见到各大large模型的集成版也并非偶然。在发论文的时候,又要不断地去内卷SOTA,今天的SOTA在明天就有可能被打败,成为了过眼云烟。极端情况下,某一篇论文正在撰写,ArXiv上就突然刷新了SOTA,又足以让研究者们头疼应该怎样应对。 同时,参数规模...

2020年, OpenAI的大作GPT-3 (Language Models are few shot learners) 横空出世,震惊整个NLP/AI圈。大家在惊叹于GPT-3 1750B参数的壕无人性同时,想必对GPT-3中的Prompt方法印象深刻。简单来说,(GPT-3中的)Prompt就是为输入的数据提供模板(例如对于翻译任务 Translate English to Chinese:...









推广返利